Behind the Myth: Can One API Call Rule Them All? (Part 1/2)
OpenRouter's Fusion plugin collapses a three-judge deliberation panel into a single model call. Part 1 puts our old and new checker agents head to head on speed, and asks whether one call is really faster than three.
Introduction
There was a lot of talk last week about OpenRouter’s Fusion model. It landed right when we had to say goodbye to the mythical Fable-tale. Was Anthropic aware it would sound that way? I’m not sure. Was it intentional? I don’t know. Either way, like the ring bearers at the Grey Havens, the Fable sailed off to the West.
This landed at a heated moment. For the first time the US government has stepped into the development of something this close to frontier AI, and it reads as a move against Anthropic, who refused to lift the guardrails built into Claude Code for the government. Was it a small revenge, or something else. We still don’t know.
But that story to one side… we had a chance to play with Fable for three days, and straight after that OpenRouter surprised us with Fable-like benchmark results, on one of their newest plugin. Their Fusion of models is a plugin that gives access to a deliberation tool across multiple frontier or less known models. The choice is yours: a fellowship of models, each from a different house, it can be Opus or Qwen, GPT or Gemini. When the plugin invokes it, a panel answers the prompt in parallel, a judge compares those responses and returns structured answer, and a final model uses that to write a better one. Apparently it approaches the benchmark Fable set previously. We tested it on one of our agents.
History of the idea
Fusion is a big move in the recent craze around mixing multiple models. It did not come out of nowhere. It is the latest step in a line of research that’s been building for about three years. It started with FrugalGPT in May 2023 [1], but like in any story history becomes legend, and legend becomes myth, and by AI timeline, 2023 is all three. That’s when Stanford researchers showed that picking the right model, not a smarter one, could cut inference costs by nearly 98%. By the end of that year we got Aurelio [2], and then came the Mixture of Agents (MoA) paper [3].
Mixture of Agents - Basic idea
Instead of routing to a single model, MoA calls several at once and feeds their outputs into an aggregator that repeatedly beat GPT-4 (in their example). The model effectively had a post-processing step: the outputs were evaluated, then folded back into the final result.
Step 1: Independent Brainstorming
You ask a question, and the system sends it to a diverse group of different AI models at the same time. Every model works independently to write its own first draft of the answer.
Step 2: Peer Review by Model
Once all the first drafts are done, the system gathers them up. It then sends your original question plus all of those first-draft answers to a second layer of AI models. It is essentially telling them: “Here is the question, and here is what the first group thought. Use their ideas to write a better answer.”
Step 3: Iteration (Optional)
This collaboration process can repeat for a few rounds. Each time, the AIs get to see the refined answers from the previous round, allowing them to correct mistakes, borrow good points from each other, and drop bad ideas.
Step 4: The Final Synthesis
After the collaboration rounds are finished, all the highly refined answers are handed over to one final “Aggregator” or “Judge” model. This final AI reads through the best ideas, resolves any remaining disagreements, and writes the single, polished final answer that you actually see.
Pros - When to Use it
The main benefits:
- Higher accuracy on complex tasks - on OpenRouter’s DRACO benchmark [8], OpenRouter’s Fusion setup using premium panel with Fable 5 and GPT-5.5 scored 69%, outperforming solo Fable score of 65.3%
- Budget efficiency - more impressively, the mid-tier model setup (Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro) scored 64.7% together, which is beating solo GPT-5.5 and Claude Opus 4.8 at roughly half the cost
This is coming within 1% of Fable’s score at roughly half the cost, which matters for teams thinking about the price of frontier models.
- Hallucination reduction - cross-checking output from several diverse models lowers the risk of factual errors compared to trusting one model’s first answer. It gives the model some breathing space.
- Free to experiment - the endpoint is currently priced at $0 per million tokens for OpenRouter’s own usage.
Cons - When NOT to Use it
- Higher latency - running 3–5 models (it supports maximum of 8 models) plus a final judge call in sequence takes longer than a single model call, which makes it a poor fit for real-time or user-facing chat.
- In our case we used it to improve one of our agents, not to serve live chat, so the latency is a cost we can absorb. It is slow, and we measure exactly how slow in the timing experiment which we will present to you.
- Multiplicative cost - the default 3-model panel plus one judge costs 4–5x more (depending how many models you use) than a single completion on the same prompt.
- Overkill on simple tasks - if the task is narrow and easy, this is an overkill. It fits complex work where agents need to think, like deep research or expert critique, for example our agentic failure detection.
- Opaque synthesis - OpenRouter hasn’t published how the judge weights responses, which is a problem for enterprise teams that need explainability.
Potential stack / architecture
The basic idea is to have some sort of orchestrator which will call out these models, and later compare them, and get the nicely structured answer.

Checker Agent
As I mentioned before, the usecase for this model is perfect for a complex work where model needs to think, reason and report important and structured information. This is why we decided to apply this on the flow for our agent who is checking if everything labelled is a failure or not. This agent is called Checker. This will be our testing agent for Fusion.
The whole idea of the Checker agent is inspired by the simplicity of Claude Code [5]. The use of the Unix like tools is well documented and the training data in these models is rich. So basic idea is that you use basic design strategy: KISS - Keep it Simple, Stupid! We gave it only two tools, grep_logs to search the logs and get_record to pull a full trace, plus the intelligence of all three models combined to find a correct verdict.
Previous implementation
We previously used Verdict [4], released by Haize Labs on February 18, 2025, a library for scaling judge-time compute. It also uses a layered, multi-model panel: its core primitive is explicitly described as a list of units in successive stages, which is nearly identical to the MoA paper. Haize Labs’ library, good as it is, hasn’t been updated in a while. The pace of AI development moves fast and we need to test what’s at the forefront, so let’s explore what OpenRouter brings to our implementation.
The Verdict [4] sits on a different branch off the same research trunk. It’s strictly for evaluation. It doesn’t produce answers, it judges them. Its paper describes composing modular reasoning units (verification, debate, and aggregation) to improve LLM-as-a-judge reliability.
We removed the Verdict layer. We lost the three independent panel votes, but that’s acceptable: the Checker only needs a single decisive answer per entity, and Fusion delivers exactly that. By the benchmark numbers it’s closing the gap with Fable. The clear win is on the code side: one call replaces three, and it frees us from a third-party voting library and its dependency chain. Whether that one call is also faster or cheaper than the three it replaces is a separate question, which we will try to answer it in Experiment D and C, respectively.
Phases of Checker
Phase A is called blind investigation. Here the Checker reads the raw logs with cold start, with no idea what triage already guessed, and greps around to form its own independent opinion. Like a detective who refuses to read the police report first, so the prime suspect’s name doesn’t bias the hunt.
Phase B is deliberation. At this stage the triage guess is revealed, and a panel of frontier models argues it out and returns one final verdict: agree, disagree, or escalate. “*Like the Council of Elrond, a panel of frontier models argues it, handle the theory, before one verdict is agreed.**“
Steps of the previous stack
- Entry: takes one entity, its logs, and the triage result.
- Blind investigation: agent inspects logs alone → blind label + evidence.
- Early exit: no triage to compare against → return the blind result.
- Verdict vote: 3 judges (Anthropic, Gemini, Cerebras) vote in parallel → agree / disagree / escalate. 3b. Fallback: tie or error → safe escalate.
- Synthesis: turn votes + triage into a final label, severity, and reasoning.
- Output: return the final result (ruling, label, severity, evidence).
New Checker flow with OpenRouter Fusion

Step of the new stack
- Entry: Checker takes an entity, its logs, and the triage result.
- Blind investigation: agent inspects logs alone → blind label + evidence.
- Early exit: blind and triage both say “no failure” → skip to output.
- Fusion: 3 models answer, a judge picks the verdict → agree / disagree / escalate. 3b. Fallback: on error → safe escalate, degraded=true.
- Validation: guardrails + source metadata → corrected ruling.
- Output: the Checker returns the final result.
What changed vs. before
- Before: Phase B was 3 separate judge calls (Anthropic + Gemini + Cerebras) through the haizelabs
verdictlibrary, then a majority vote tallied in our code. - Now: Phase B is one
openrouter/fusioncall. OpenRouter runs the panel and the judge server-side and returns a single collapsed ruling. - Unchanged: Phase A stays on the native Anthropic SDK; the early-exit gate and post-validation guardrails are the same.
How does one call do the work of three?
The three calls don’t disappear, but they move. On our side it’s one openrouter/fusion request. On the server side, OpenRouter fans the prompt out to three models in parallel (each with web_search/web_fetch), then a judge compares their responses and emits structured JSON and the final model uses that to write the answer [7]. The panel still costs three-plus completions, hidden behind one request and one price.
Caveats: deliberation is bounded to one level (no recursive Fusion), and ~75% of the lift comes from the judge, not panel diversity [7]. So latency isn’t a given: we traded three parallel calls for a panel-plus-judge chain, and Experiment D measures the result.
Experiments
To put the old and new agents on equal footing we ran them against an identical set of previously labelled results, with the same two tools (grep_logs to search the logs and get_record to pull a full trace) and the same prompts. The only thing that differs between the two is the deliberation step, so whatever we measure comes from that change and nothing else.
This first part covers the timing experiments:
- Experiment A, old-agent (haizelabs) timing baseline: per-entity Phase A/B time and rulings.
- Experiment B, new-agent (Fusion) timing: same 6 entities, head-to-head time and rulings vs A.
- Experiment D, statistical significant timing: 31 paired entities to test “which is faster” with significance.
The cost experiments (C - cost per phase and E - cost per model) will be published in Part 2.
Experiment A and B - Smaller smoke test Timings
Experiments A and B are the small, paired smoke tests we ran before committing to bigger.
Experiment A times the old haizelabs agent across six previously labelled entities, recording Phase A and Phase B separately.
Experiment B then puts the exact same six entities through the new Fusion Checker flow.
The goal here was modest: confirm the script runs end to end without falling over, and check that quality survives the swap, meaning both agents flag the same failures under the same tool limit.
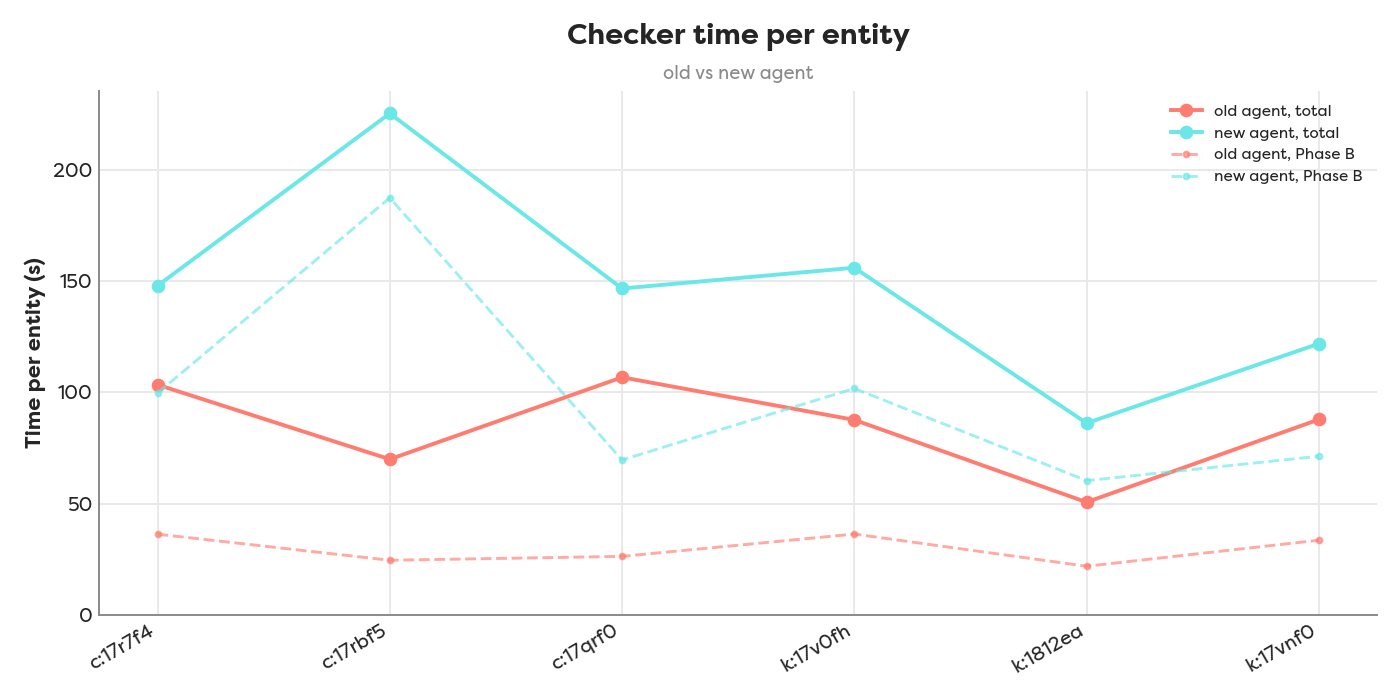
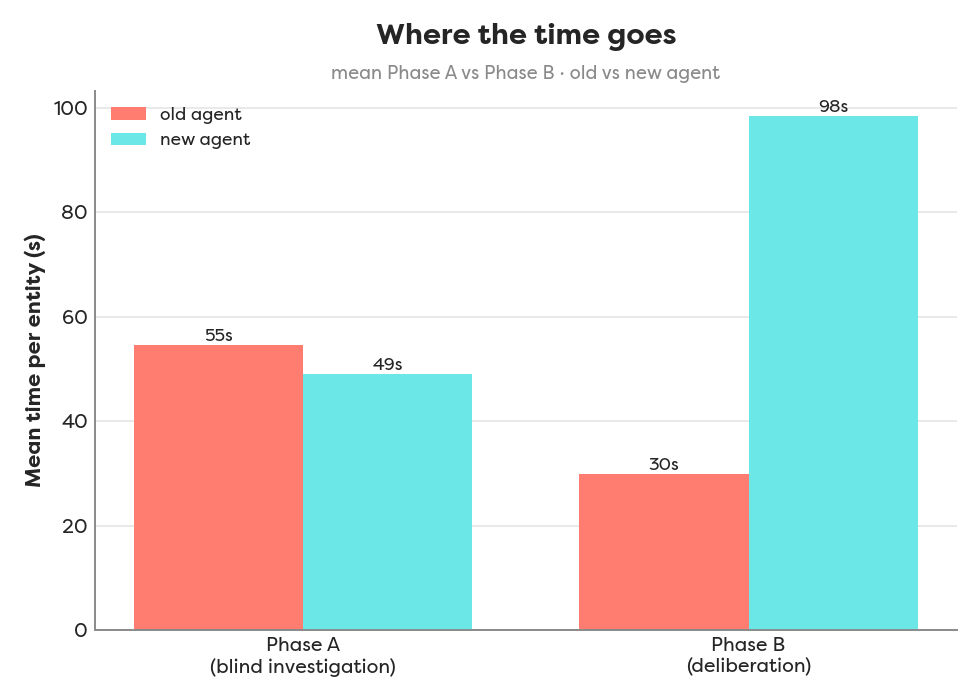
Purely on timing, the new Fusion Checker (teal) ran slower than the old haizelabs agent (red) on all six entities, and the phase breakdown shows why: Phase A stays roughly level (49s vs 55s mean) while Fusion’s Phase B deliberation balloons to 98s against the old panel’s 30s.
Fusion didn’t make the deliberation faster; verdict’s parallel 3-judge vote beat it on both (~3× speed, slightly lower cost). What Fusion buys is one API call instead of three, simpler code, and dropping the haizelabs/litellm dependency.
Speed (6 entities, sequential):
- Deliberation (Phase B): verdict 30s vs Fusion 98s mean. Verdict’s 3 parallel judges were ~3× faster than Fusion’s single call (the panel runs premium latest models server-side, plus retries).
Two caveats
- Small sample, on purpose. This started as a 6-entity timing run (3 entities for cost), kept small because the goal was a quick, cheap comparison rather than a benchmark.
- Further on, in initial setup for Experiment C and E, where we measure cost, the cost was a floor, not a ceiling, because Fusion’s measured cost was only counting what we could see (in a setup panel 1 > panel 2 > panel 3 > Opus judge, we could see only Opus judge cost).
This makes deliberation potentially more expensive than verdict. This is because currently OpenRouter offers a promption of $0 during experimentation phase.
End-to-end, summed over all entities:
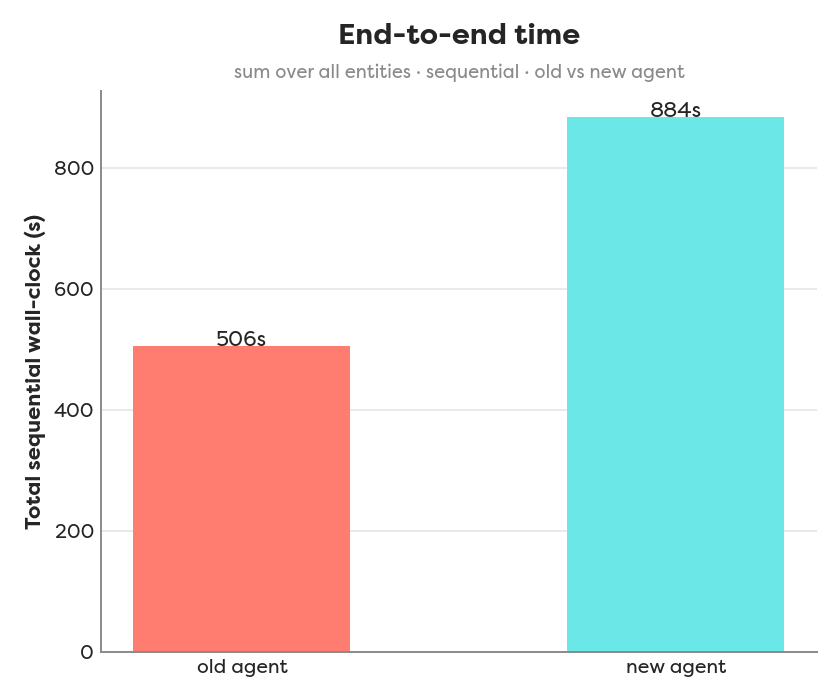
- End-to-end: verdict 506s vs Fusion 884s. Verdict was ~1.75× faster overall.
- Fusion’s only speed win is Phase A (49s vs 55s), and that’s from an unrelated tool-budget cap, not the deliberation.
Did the checker’s rulings stay consistent after replacing the three independent votes with a single Fusion call?
Mostly, yes. On the same 6 entities, Fusion and the old 3-judge verdict reached the same ruling on 5 out of 6. The one divergence is the borderline case: on the no_failure keyset group, the 3-judge verdict disagreed and flipped it to likely_failure, while Fusion agreed with no_failure. Without ground truth to settle this disagreemend, we put it as ordinary LLM non-determinism rather than a real regression. At the same time, the keyset groups are the parts of our product which is giving us room for revision, as the models do not have much content to judge, but only structural pointers. But this is outside discussion which is not part of this article. It’s a sanity check.
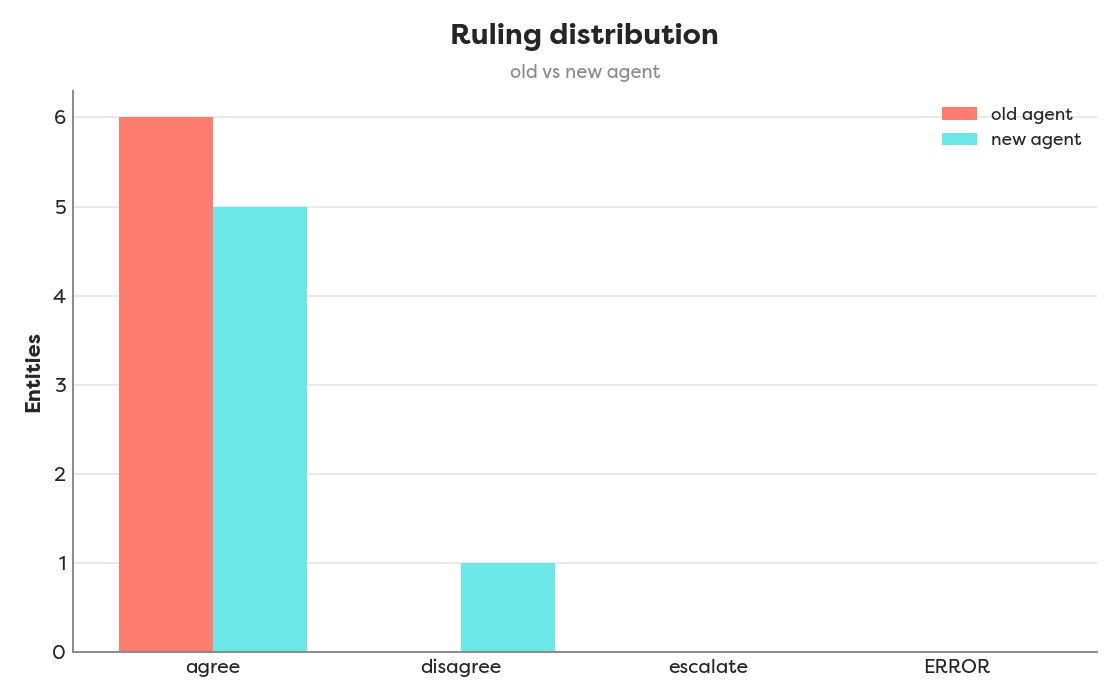
This single disagreemend is a simple sanity check, not a verdict, but it cleared the way for the larger, statistically powered run in Experiment D.
Experiment D - The Big Timing Question
Experiment D is the one we care about for this part. The deliberation step is exactly what we swapped: verdict’s three judges running in parallel versus a single Fusion call that fans out to its panel server-side. So the question is simple:
- “Did collapsing three parallel votes into one call make the Checker faster, slower, or about the same?”
It is the run that decides whether Fusion’s “one call can replaces three”. Do we have a latency win, a latency cost? A single small run can’t answer that, so a larger batch was build to move past wonder and report timings.
Results for Experiment D in charts
The statistically significant run reveals the timing per entity
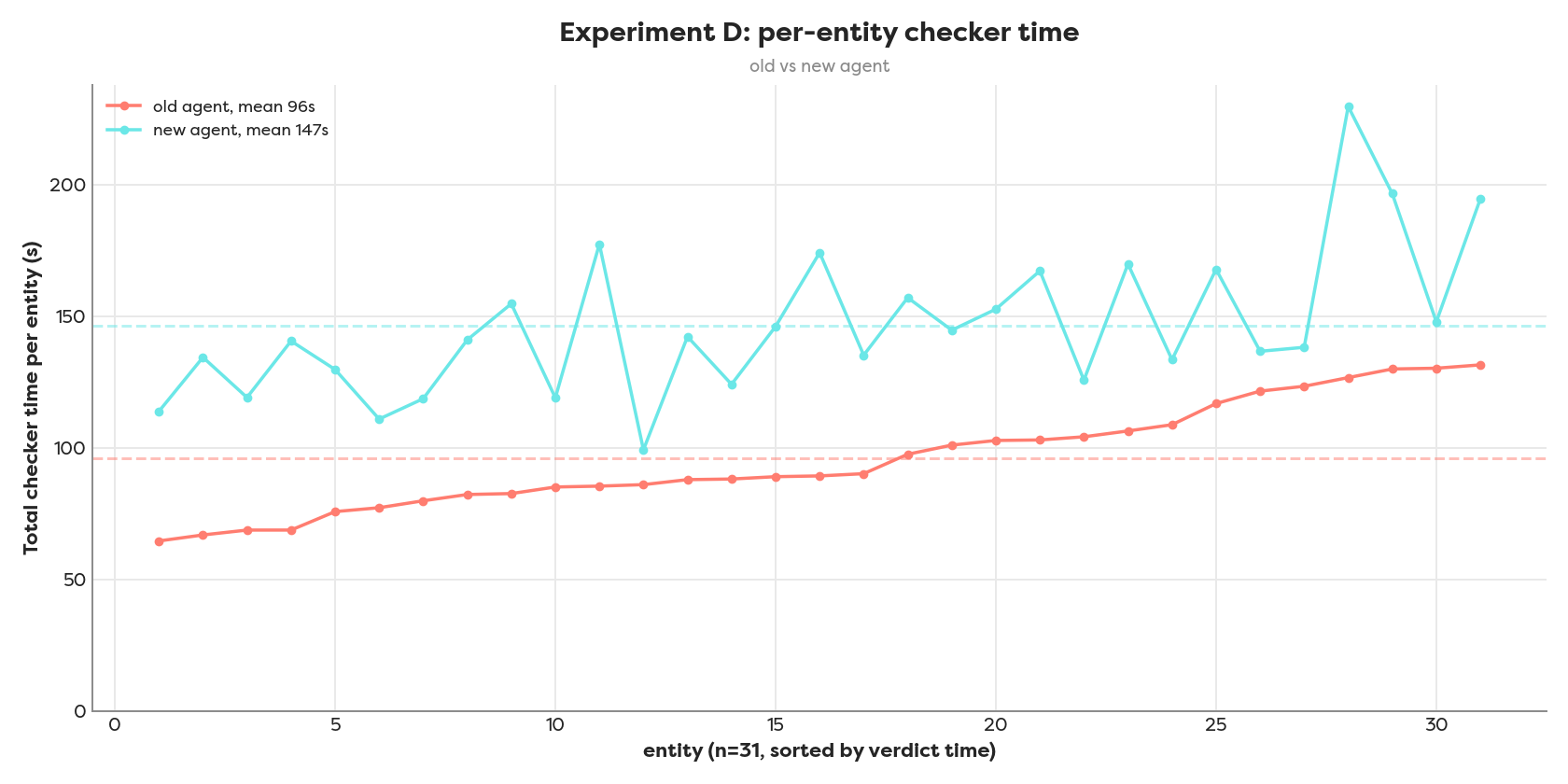
Is Fusion really faster for our usecase, and by how much?
Looking at the results, no, it is not faster. We measured the verdict -> Fusion switch on identical data (same 31 entities, same triage results). The “one call replaces three” claim is true for code simplicity and one fewer dependency, but not for latency or cost of the deliberation:
Conclusion
For the three days which we had time to play with Fable in our company, and like the Ring bearers at the Grey Havens, the Fable as well sailed off, it is sad to see it in the obscurity, but the best tales have a way of coming back. This brings a lot of debate regarding who can control models and when is it safe or not safe to be used by the public, or is it some sort of competition trick which one government was scared that the other will have access and it can distil the information and make similar product. It is still unclear as the court case between Anthropic and the U.S. government plays out [6], but we might find out soon. The AI saga continues…
On the engineering side, we’ve done the part that doesn’t need a benchmark to justify it: we rebuilt the Checker around a single Fusion deliberation call instead of a three-judge panel, dropped a third-party voting library and its dependency chain, and ended up with one prompt to maintain instead of three. That is a simplicity win regardless of what the timer says. On speed, the timing runs above give the first clear read: the consolidated Fusion call did not win, and its deliberation was the slower half.
In brief: The two flows agree on 5/6 entities, and switching verdict→Fusion buys simpler code and one fewer dependency, not speed. Verdict’s parallel 3-judge vote was ~3× faster at the deliberation (Phase B 30s vs 98s mean) and ~1.75× faster end-to-end (506s vs 884s). Phase A is near-identical (55s vs 49s), so the whole gap comes from Fusion’s slower Phase B deliberation.
So here is where we’ll pause Part 1. We have laid out the idea behind Fusion, why mixing models is having its moment, how we reframed our Checker around one deliberation call, and the timing from Experiments A, B and D. In the next article we’ll put the dollars side by side: the per-phase and per-model cost of what each agent spends, how that maps to real model usage, and what the benefit of this implementation actually turns out to be. See you then.
References
[1] L. Chen, M. Zaharia, and J. Zou, “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance,” arXiv:2305.05176, May 2023. Available: https://arxiv.org/abs/2305.05176
[2] Aurelio Labs, “Semantic Router: superfast AI decision-making for LLMs and agents,” GitHub repository, 2023. Available: https://github.com/aurelio-labs/semantic-router
[3] J. Wang et al., “Mixture-of-Agents Enhances Large Language Model Capabilities,” arXiv:2406.04692, Jun. 2024. Available: https://arxiv.org/abs/2406.04692
[4] N. Kalra and L. Tang, “Verdict: A Library for Scaling Judge-Time Compute,” arXiv:2502.18018, Feb. 2025. Available: https://arxiv.org/abs/2502.18018
[5] MinusX, “What makes Claude Code so damn good (and how to recreate that magic in your agent)!?,” MinusX blog, Aug. 21, 2025. Available: https://minusx.ai/blog/decoding-claude-code/#42-this-is-important-is-still-state-of-the-art
[6] “Anthropic Employees Accuse Trump Administration of Targeting Them,” The New York Times, Jun. 17, 2026. Available: https://www.nytimes.com/2026/06/17/technology/anthropic-trump-administration-fable.html
[7] OpenRouter, “Fusion — Multi-model AI Analysis with OpenRouter,” OpenRouter Documentation, 2026. Available: https://openrouter.ai/docs/guides/features/plugins/fusion
[8] J. Zhong et al., “DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity,” arXiv:2602.11685, Feb. 2026. Available: https://arxiv.org/abs/2602.11685
Wrap-up
AI agents can look fine in demos and still fail in production. Moyai helps teams catch reliability issues early with clustering, evaluation, and actionable alerts.
If that sounds like the kind of tooling you want to use — try Moyai or join us on Discord .